
Prototype 2: Custom electronics mount integrated for JETSON and Raspberry Pi
Prototype 2: Custom electronics mount integrated for JETSON and Raspberry Pi

Prototype 3 - Top View: Modular design with detachable Jetson, Raspberry Pi, and hip back plate using M3 and M4 screws

Prototype 3 - Side View: Hip back plate visible, showing complete modular assembly with M3/M4 screw integration
Goal: Develop a compact, modular electronics board for on-body deployment during exoskeleton-assisted walking.
Challenge: Original setup was bulky and unstable, with dangling wires and poor component integration. Initial PLA material (Prototype 2) was too brittle and had low temperature resistance, limiting flexibility and durability for wearable applications.
My Contribution: Designed a 3D-printed backplate with embedded cable channels and modular Pi/Jetson mounts for system stability and upgrade flexibility. Evolved from PLA to PETG material for improved ductility, stress resistance, and higher glass transition temperature, enabling better vapour smoothing and reduced printing failures.
Skills Used: CAD (Solidworks), 3D Printing (Prusa), Embedded System Integration, Material Science.
Outcome: Enabled safe, wearable deployment with organized layout and modularity for field testing.
Goal: Create a torque prediction model that generalizes across users to minimize metabolic cost during walking.
Challenge: Initial model overfit to individual training subjects and failed to generalize to unseen data.
My Contribution: Implemented leave-one-subject-out cross-validation (LOSO CV) to evaluate generalization across participants, using subject-independent training-validation splits. Developed comprehensive feature engineering pipeline including gait phase detection, biomechanical feature extraction, and temporal signal processing.
Skills Used: Python (Scikit-learn), MATLAB, Model Validation, Statistical Evaluation, Feature Engineering, Signal Processing.
Outcome: Reduced MSE by 28%, narrowed the training-validation gap, and increased robustness to user variance.
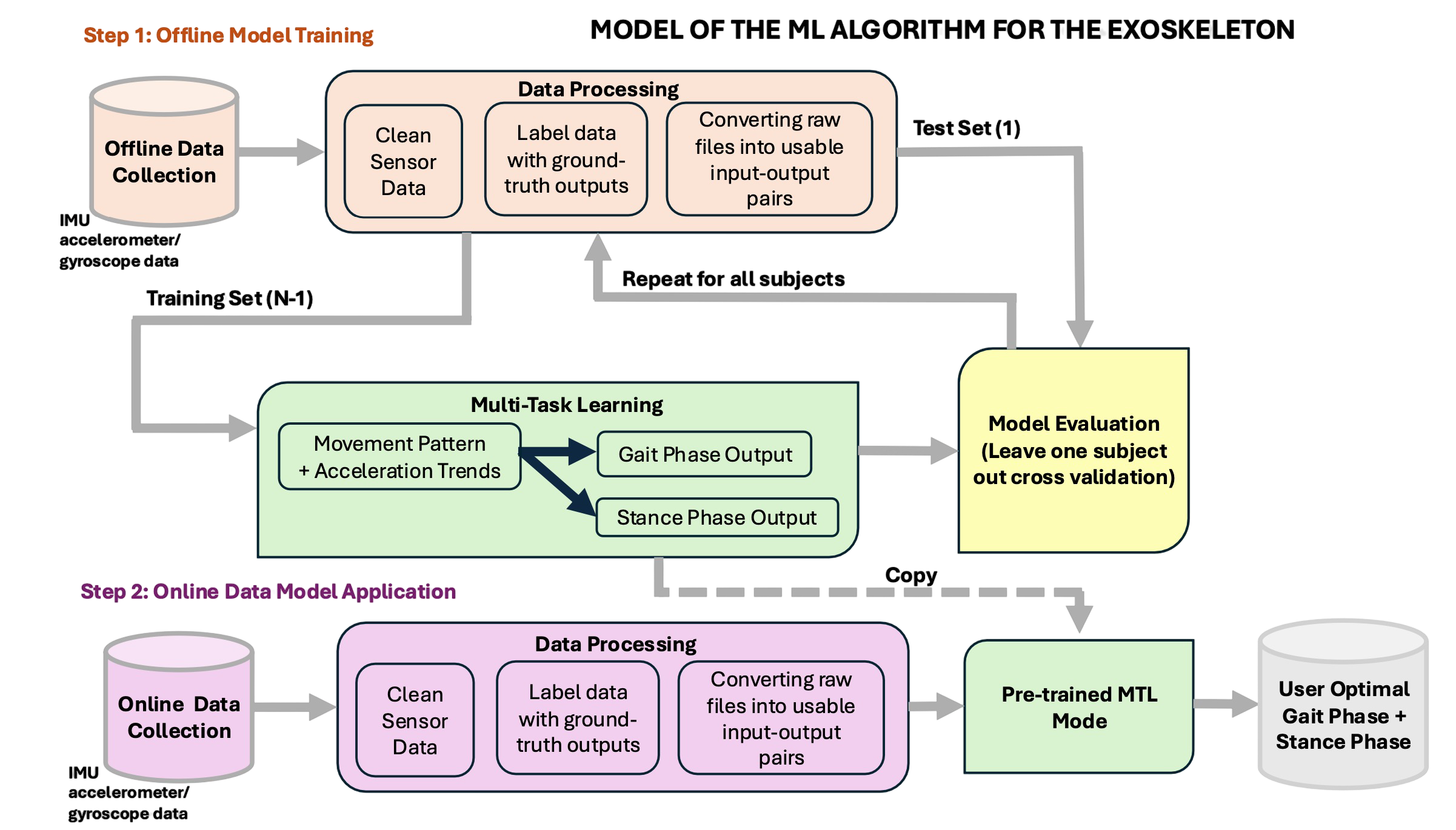
Structure of the Ankle Exoskeleton Torque Prediction Pipeline
Outlier Mitigation: Integrate offline data preprocessing for anomaly detection using Z-score and domain-specific gait metrics.
Real-World Deployment: Transition to online testing with live gait data to validate robustness under dynamic conditions and varied terrains.
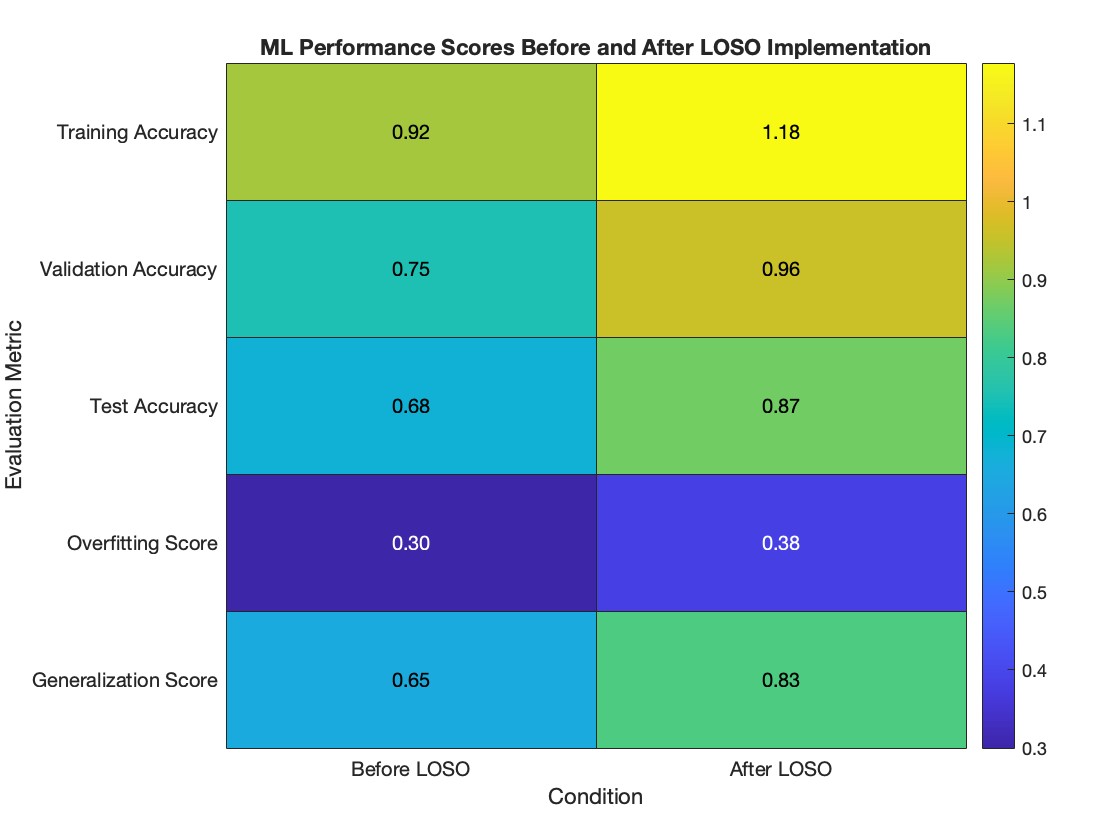
Validation Improvement (MSE) from LOSO CV — plotted in MATLAB